Customer benchmarking — the practice of identifying where a customer can improve or is already doing well by comparing to other customers – helps Customer Success Managers to deliver unique value to their customers. The comparative insights from benchmarking motivate customers to make changes that produce better outcomes with their solutions. I’ve written more about this link in a recent post.
SaaS customer success leaders publicly encourage greater adoption of this practice. Peter Armaly, a customer success expert with Oracle Marketing Cloud, argued in his presentation at the 2016 Customer Success Summit that it should be a foundational activity of CSMs. In her featured post earlier this year, Kia Puhm, a customer experience consultant and a former executive with Adobe, Eloqua and Blueprint, advocated using customer benchmarking in every QBR, annual renewal discussion and proactive strategic meeting with customers. At the TSIA World conference in May, Rachel Barger presented how Lithium Technologies’ CSMs use their benchmarking program to make recommendations to customers.
I’ve found that SaaS vendors use seven distinct strategies to empower CSMs with customer benchmarking. The first two are longstanding strategies that rely on third-party data. The other five strategies leverage the data that is a byproduct of the vendor’s customer relationships and usage of their solutions. The last two of these five progressively use artificial intelligence to further automate the task.
Strategies Defined
Strategy 1: Customer Benchmarking using Industry Surveys
CSMs can leverage the benchmarking work of industry associations and research firms to help customers set performance targets, identify areas for improvement, and recommend best practices. These independent organizations sponsor benchmarking surveys that are completed by representatives of companies in the industry. The sponsor creates the survey, collects the data and does the analysis. The aggregated, anonymized findings are accessible in published documents or online tools for their members and customers.
With this strategy, the sponsor does all the work, but self-reported data can be unreliable and not specific to the SaaS vendor’s solutions or even customers.
Strategy 2: Customer Benchmarking using Best-Practices Studies
CSMs can help customers strive for superior outcomes by comparing their customer’s practices with the best practices. This approach studies a key business process of several companies that are perceived as the best in their industry and agree to participate. A third-party organization or the SaaS vendor sponsors an on-site study to collect mostly qualitative data on practices, key metrics and business context. The sponsor analyzes the data and reports what they’ve learned.
The sponsor does all the work for this strategy too, and superior practices can be found. But the SaaS vendor’s customers may see the practices of the best companies as unrealistic or irrelevant.
Strategy 3: Customer Benchmarking using Vendor Surveys
SaaS vendors can do their own benchmarking survey when their customer base is sufficiently large to obtain a representative sample. They analyze the aggregated data and share summary findings with their customers. A CSM collects data from an individual customer to compare how they’re doing versus the aggregated, anonymized results at a more granular level.
This strategy benefits from a survey that’s tailored to the vendor’s customer base, but it suffers from the same reliability drawbacks as Strategy 1.
Strategy 4: Customer Benchmarking using Data Scientists
When requested by CSMs, data scientists use their skills with statistics and modeling to mine the SaaS vendor’s data for deep, insightful correlations and comparisons. This is often a one-off solution, although procedures can be set up for recurring needs. The work involves advanced techniques such as regression analysis, stochastic frontier analysis and data envelope analysis using sophisticated software tools.
Data scientists may find unexpected insights by analyzing their own solutions and customer relationship data. The lack of scalability handicaps this strategy.
Strategy 5: Customer Benchmarking using Business Software Reports
By running reports on their aggregated customer data, CSMs can easily see how a specific customer compares with other customers on a given metric. A company’s adopted CRM, BI or CSM software platforms usually provide this capability. For example, customer success software platforms such as Amity and Gainsight generate a scorecard summary which lists the SaaS vendor’s customers and their performance on key metrics. A CSM sorts the list by a selected metric, calculates averages and filters the customers into a relevant group using various attributes.
CSMs can generate reports as needed with this strategy, but the reports contain data, not insights, and support only basic, manual analysis to find insights.
Strategy 6: Customer Benchmarking using your SaaS Product
SaaS vendors can enable their customers to benchmark themselves within their own software solution, which can be used by their CSMs, too. SAP, Apptio, ServiceNow, InsightSquared, Samanage, IQNavigator, ADP, Zendesk and other companies offer this capability. Using the vendor’s anonymized, aggregate customer data, a customer can compare itself against other customers of the same solution on various metrics, and CSMs can compare them also. SaaS companies develop basic benchmarking features in-house (such as scorecards, rankings, averages and several peer groups) or embed technology from specialized benchmarking software vendors like OnlyBoth that do this along with automated, in-depth analysis and narrative reporting.
Customers can get answers to some benchmarking questions on their own, but this strategy doesn’t make use of the internal vendor data that provides valuable benchmarking insights to CSMs but isn’t available for customer viewing.
Strategy 7: Customer Benchmarking using Specialized Benchmarking Software
With advanced automation available from several software firms, CSMs can get many more actionable and deep comparative insights for each customer quickly. Waypoint Group’s TopBox benchmarking module automatically analyzes for significant correlations between customer feedback responses and outcome metrics such as NPS and customer health for several customer peer groups. The Customer Benchmarking Engine available from OnlyBoth automates the data analysis, insight discovery, and narrative reporting by using artificial intelligence and the SaaS vendor’s data.
CSMs benefit from automated analysis which produces many more and deeper insights for each customer, overcoming the limitations of business software reports and data scientist scalability. The challenge is that CSMs are called on to make more judgments on which insights to use and share.
For a brief guide to the pros, cons and requirements of each strategy, see the paper “Pioneering SaaS Customer Success Leaders Seek New Customer Benchmarking Strategies to Deliver Value to Customers.”
Final thoughts
According to research by TSIA, CSMs at 25 percent of SaaS vendors are already using customer benchmarking. These pioneers have recognized the opportunity to enhance customer relationships and sustain their journey with the insights that only they can provide, because only they have the solution-specific data. With the data and strategies that are now accessible, more customer success organizations are poised to adopt this practice.
Jim Berardone

 Surprisingly, this simple trick works. People change their behaviors when they see how they stack up against others. In multiple experiments run by the utility companies, providing benchmarks reduced overall power usage 2%.1 That may not sound like much, but across millions of homes the savings are substantial, helping power companies meet their government-mandated conservation goals. Similar outcomes from communicating descriptive norms have been shown in hospitality (reusing towels more often),2 voting (increasing turnout),3 and charitable giving (boosting the number of donors).4
Surprisingly, this simple trick works. People change their behaviors when they see how they stack up against others. In multiple experiments run by the utility companies, providing benchmarks reduced overall power usage 2%.1 That may not sound like much, but across millions of homes the savings are substantial, helping power companies meet their government-mandated conservation goals. Similar outcomes from communicating descriptive norms have been shown in hospitality (reusing towels more often),2 voting (increasing turnout),3 and charitable giving (boosting the number of donors).4 OnlyBoth has launched a County Benchmarking Engine as its newest showcase application and public service, leveraging the availability of federal as well as private-sector data on all 3,143 U.S. counties. We collected data on 104 county attributes by these topics:
OnlyBoth has launched a County Benchmarking Engine as its newest showcase application and public service, leveraging the availability of federal as well as private-sector data on all 3,143 U.S. counties. We collected data on 104 county attributes by these topics:

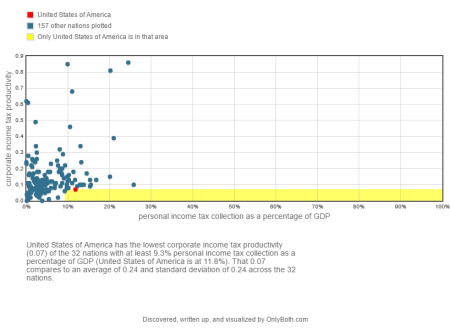 A separate insight reveals that the U.S. has the lowest corporate-income-tax productivity of the 17 nations with an agriculture sector as a percentage of GDP of at most 1.6% (the U.S. is at 1.2%).
A separate insight reveals that the U.S. has the lowest corporate-income-tax productivity of the 17 nations with an agriculture sector as a percentage of GDP of at most 1.6% (the U.S. is at 1.2%).
{kind=link}