 Welcome to the inaugural blog post for OnlyBoth, founded in March 2014. Let’s consider what is OnlyBoth’s founding idea.
Welcome to the inaugural blog post for OnlyBoth, founded in March 2014. Let’s consider what is OnlyBoth’s founding idea.
Data has been abundant for a while, but much more of it is coming for several reasons. First, the web’s rise has enabled the decentralized production of data and text. Data can be created, assembled, combined, and published by anyone. Second, the emergence of sensors, either stand-alone or embedded in multi-purpose devices, has automated data creation and given rise to the big data phenomenon.
Let’s limit our discussion to a data table – or spreadsheet – whose rows are entries of interest, and whose columns are various attributes of the entries. If the data table entries are cities, then attributes could be population, region of the country, whether the mayor is new, the set of pro sports teams, etc.
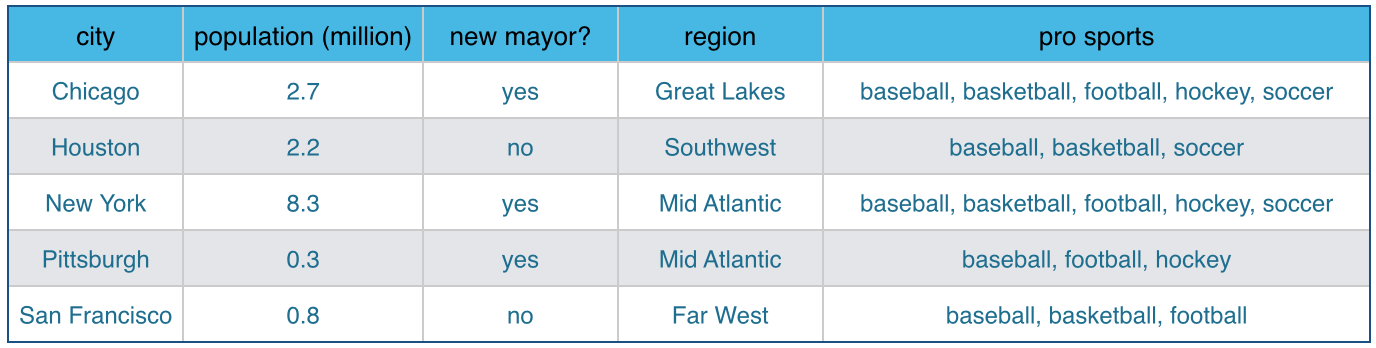
How does one gain advantage from data tables? Let’s list some interesting questions about data whose answers can be automated. The field of statistics answers some, e.g., What is the standard deviation of a data attribute? What two variables are most correlated? What causal relationships are suggested by the data? What entries are outliers?
Separately, computer science has contributed its own questions which involve sophisticated analysis. Let’s list the usual questions that data mining can answer.
- What are natural groupings in the data? Answers to this are based on clustering. Clustering has many uses, for example, to segment a customer base into coherent groups that can be sent a same marketing message. Or, in text search engines, clustering was used by Vivisimo (now part of IBM) to group search results into dominant themes.
- What are group patterns or regularities in the data? A famous example, again from marketing, is that young men who buy diapers on a Friday afternoon also tend to buy beer.
- For a newly arrived entry, can I predict its value for a specific attribute? If you’re a bank, with historical data on customer creditworthiness and observable characteristics, you may want to predict how creditworthy a prospective debtor will be. Or a company may want to predict what customers will leave (“churn”) over the next few months.
OnlyBoth’s founding idea is a new question to ask about data that hasn’t been posed statistically or computationally, much less solved: What’s unique, distinctive, or special about an individual entry? Of course, the question wasn’t invented in a research lab, but was taken from human practice (read the story here) and then developed in an academic lab with support from the National Science Foundation. Marketers, competitors, scientists, sports fans, tourists, investors, et al. have always been interested in how certain people, places, things, and events are unique.
Of course, to fully answer the question means to write it up as a good sentence or paragraph, which has its own technical challenges. Also, some answers are insightful and others not; one has to figure that out. OnlyBoth does both discovery and writing, but not only both!
In brief, unlike most data mining, which focuses on group patterns or predictive analytics, OnlyBoth’s founding idea is to discover individual insights ready to be read, understood, and sometimes acted upon, by people.
Raul Valdes-Perez

{kind=link}